
From User to Architect
How to Stop Using AI and Start Delegating to It

I have always been an outliner.
Before any presentation I was going to give, whether a lecture, a keynote, or a faculty workshop, I would sit down and build an outline first. Detailed, structured, sometimes color-coded down to the sub-point. I could see the slides in my head before I ever opened PowerPoint. I knew what each one would say, roughly how it would look, the arc of the whole thing from the opening provocation to the closing turn.

And then I would spend four or five hours building the deck, and it would come out nothing like what I had imagined. The font choices fought me. The image I wanted didn’t exist. The animation that was supposed to reveal the argument one beat at a time instead revealed how tired I was at eleven at night. The deck that reached the audience was always a degraded copy of the one in my head.
The first time I fed one of those outlines into Gamma and watched it produce a fully realized presentation in under a minute, one that needed only one or two small adjustments before it was ready, I had one of those moments you don’t forget. It closed a gap I had been living with for years: the gap between what I could see and what I could make. The vision in my head and the artifact on the screen finally matched, and I hadn’t spent an evening losing the difference.
That moment changed how I work. More importantly, it changed how I think about work.
The Gap Between What You Can See and What You Can Make
Most people experience AI as a tool that helps them do things faster. You write a prompt, you get an output, you edit it, you move on. The AI is a very fast assistant sitting beside you, and you are still the one doing the work. You are still in the chair, still making every decision, still the bottleneck through which every task must pass.
That is a legitimate and valuable way to use these tools. I used them that way for the better part of a year, and the productivity was real. But it has a ceiling, and the ceiling is you. However fast your assistant types, you can only supervise one conversation at a time. The faster-assistant model makes you a quicker craftsman. It does not make you anything else.
What I want to describe is a different relationship, one where you stop being the person who does the work and become the person who designs the system that does the work. Your primary output is no longer the thing itself. It is the pipeline that produces the thing, running whether or not you are watching it.
I call this being a pipeline architect. The shift from AI user to pipeline architect is, I think, the most consequential transition available to knowledge workers right now. Most people haven’t made it. Most people don’t yet know it’s on the table.
The difference between the two is not subtle once you’ve felt it, so it is worth drawing the line clearly.
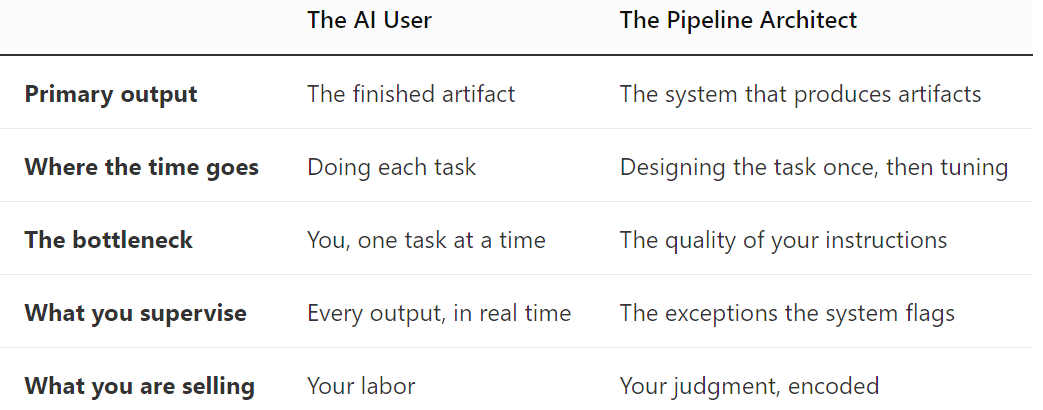
The bottom row is the one that matters. As a user, you sell your hours. As an architect, you sell your judgment, written down once in a form a machine can execute a thousand times.
What a Pipeline Actually Is, and Where Mine Lives
A pipeline is a sequence of steps where the output of one step becomes the input of the next, and at least some of those steps involve AI making decisions you do not supervise in real time.
That last clause carries the weight. A pipeline is more than a workflow. Plenty of people have workflows, and a workflow with a human approving every step is just a slower version of doing it yourself. A pipeline has AI participating in the decisions inside the flow, not just carrying the bags. Classifying. Scoring. Routing. Deciding what happens next while you are asleep or teaching or three tasks downstream.

Here is a concrete example from my own week.
I subscribe to far too many Substacks. I find a writer doing something interesting, I sign up enthusiastically, and I never unsubscribe. The result is an inbox where not everything deserves the same slice of my attention. Some essays are extraordinary and reshape how I think about a problem for a week. Some are good. Some are competent and forgettable. And some I would have been measurably better off never opening.
So I wrote a scoring guide: a rubric describing what I actually value in a piece of writing. Not vague preferences but specific signals. Does the writer anchor claims in named people and dated events, or float in abstraction? Is there an argument with a turn in it, or just a position restated five ways? Does the piece earn its length, or is it a tweet wearing a trench coat? I gave each signal a weight and a short description of what a high score and a low score look like in practice.
Then I built a pipeline that applies that guide to every Substack essay that lands in my email before I ever see it.
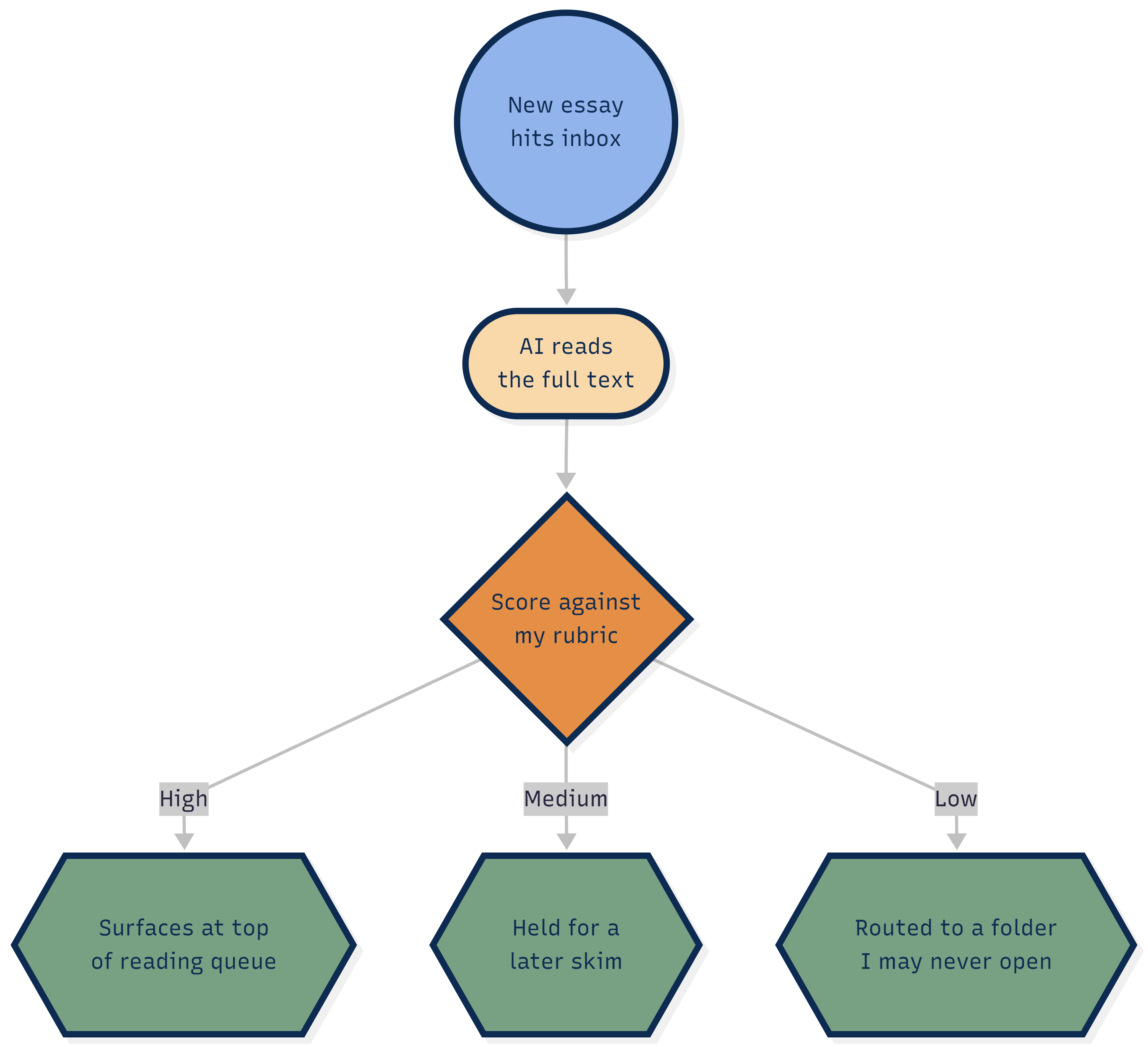
For the first month I spot-checked obsessively. I pulled essays it had scored high and asked whether I agreed. I pulled essays it had scored low and asked whether I had missed something the rubric couldn’t see. Twice I found a real disagreement, traced it back to a vague line in the scoring guide, and rewrote that line to be sharper. Then the spot-checking faded on its own. Not because I stopped caring, but because the scores had converged close enough to my own judgment that almost nothing I genuinely wanted was slipping into the folder I never open.
I had externalized my taste. I had taken something that lived only as a feeling in my reading and written it down precisely enough that a machine could apply it at three in the morning to an essay I hadn’t seen yet. Once I trusted that the externalization was faithful, I stepped back and let it run.
That is a pipeline. The decision about what deserves my attention now happens before my attention is ever spent.
The Principles I Learned the Expensive Way
Not everything is worth automating. Not everything should be automated. And plenty of tasks that look like obvious candidates turn out to be terrible ones. Here is the checklist I now run before I invest a single hour in building a pipeline, with the Substack system as the worked example.
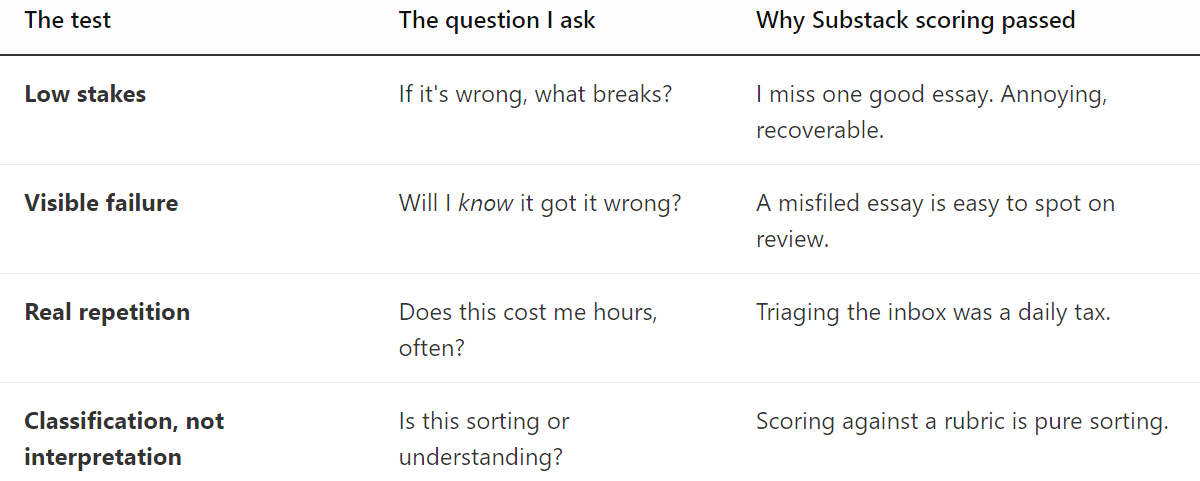
Low stakes, low drama. The best first pipeline is one where failure costs almost nothing. My scoring system failing means a good essay sits in the wrong folder for a week. I did not begin by automating anything where being wrong carried real consequence: no client deliverables, no anything that touched another person’s money or trust. You will need that forgiveness while you are tuning, because early on the system will be wrong in ways you didn’t predict, and you want those wrongs to be cheap.
Failures should be loud. This is close to the first principle but distinct, and the distinction is the whole game. The direction of failure matters more than its frequency. A pipeline that fails loudly, that produces an obviously wrong output you catch at a glance, is one you can fix. A pipeline that fails quietly, that produces a subtly wrong output that looks correct, will erode your work for months before you notice. Before I build anything I ask one question: if this gets it wrong, will the wrongness announce itself, or will it hide? If it hides, I don’t build it.
Repetition is the threshold. I have a rough rule. I do not seriously consider automating a task unless it eats at least an hour of my day, or it is something I do regularly that costs three or four hours each time. The sweet spot looks like this: a job that takes me four hours every week, where the pipeline does it in thirty minutes. That ratio is what justifies the cost of building. One-off tasks almost never clear the bar, because the time you spend designing the system exceeds the time the system will ever save. The inbox triage qualified easily; it was a tax I paid every single morning.
Classify, don’t interpret. This is the principle I hold most firmly, and I traced its full reasoning in a recent essay on discernment. AI cannot truly interpret. It cannot bring duration, formation, and skin in the game to its encounter with a text the way a human reader can; it processes the input in front of it in the present tense and the transaction ends. But AI is extraordinary at the adjacent task: classification. Sorting. Scoring against a rubric. Routing by criteria. The best pipelines hand AI the classification work and keep the interpretive work for yourself. The moment you catch yourself asking a model to make a judgment that requires genuine understanding of context, relationships, or stakes, you have found a step that must stay human. My rubric scores essays. It does not tell me what they mean.
Use the right model for the right role. This one took me a while, and it has made more difference than any single prompt I have ever written. Different language models have characteristic strengths, and a mature pipeline casts them like a director casts actors instead of defaulting to one model for everything.

In my pipelines, Claude is almost always my Red Hat agent. Before I commit to building anything, I hand Claude my implementation plan and ask it to attack: find the failure modes, name the assumptions, tell me what I am not seeing. When I designed the Substack scorer, Claude caught a problem I had walked right past. My rubric rewarded specificity, which meant a dense, citation-heavy essay would reliably score high even when its argument was wrong. The system, Claude pointed out, would learn to surface confident, well-sourced essays regardless of whether they were any good, and I would slowly let my reading be steered toward a certain texture rather than a certain quality. I added a separate axis for that. I would not have seen it until months of subtly skewed reading had already happened.
Gemini is the workhorse. For the repetitive classification, the scoring, the ingestion work that happens at volume, Gemini carries the load without complaint and without drama. Running multiple models in conversation with each other, each doing what it does best, is itself a form of pipeline architecture. You are no longer using AI. You are directing it.
Why the Outline Stopped Being For Me
When I fed that first outline into Gamma and watched the deck assemble itself, the thing that changed was not only my evening’s workload. It was my relationship to my own vision.
I started outlining differently almost immediately. More ambitiously, because the cost of ambition had dropped. More precisely, because precision now paid off instead of evaporating at eleven at night. I began adding markdown formatting, structural cues, little bracketed notes about tone and emphasis that were no longer for me. They were instructions to the system. Somewhere in there the outline quietly stopped being a sketch and became a specification, and I became, without quite deciding to, someone who writes instructions for machines as a primary creative act.

That is a strange thing to notice about yourself. It is also, I think, where the most interesting work is happening right now for knowledge workers who are paying attention. You are not just getting faster at what you used to do by hand. You are becoming someone who designs systems that produce work at a consistency and a volume you could never sustain manually. The advantage no longer lives in any single output. It lives in the architecture, and architecture compounds while you sleep.
Where to Start, Which Is Smaller Than You Think
If you have never built a pipeline, begin smaller than your ambition wants to.
Find one task that meets the four tests above: low stakes, loud failures, real repetition, and classification rather than interpretation. Write down every step of how you currently do it, by hand, in order. Then look for the steps that are repetitive and rule-based, the ones where you are applying a standard rather than exercising judgment. Those are your candidates. The judgment steps stay with you.
Write the rubric. The scoring guide, the classification criteria, the standard, whatever form it takes for your task. Be specific to the point of discomfort. The precision with which you can articulate what good looks like sets the ceiling on how well the pipeline will ever perform, because the rubric is your taste made legible to a machine. A vague rubric produces a vague system that you will never quite trust and never quite step away from.
Then build the simplest version that runs end to end. Spot-check it obsessively for the first few weeks, the way I did. Tune the guide where you and the system disagree, since the disagreement almost always points at a sentence in your rubric that was softer than your real judgment. Spot-check less. Then, one ordinary morning, notice that you have not checked it in a week and nothing has gone wrong.
That is the moment you have become, quietly and without any announcement, someone who delegates to AI rather than someone who merely uses it. It is a different kind of professional than you were a month earlier, and it takes some getting used to.
It is also, I am fairly sure, exactly where the work is going.